그래프, 트리 등의 자료구조에서 탐색하는 알고리즘이다.
BFS : 너비 우선 탐색

그래프/트리의 가까운 노드부터 방문하여 검색한다.
Queue 자료구조를 이용하며 다음과 같이 동작한다.
- 탐색 시작 노드를 큐에 삽입하고 방문 처리를 한다.
- 큐에서 노드를 꺼내 해당 노드의 인접 노드 중에서 방문하지 않은 노드를 모두 큐에 삽입하고 방문 처리를 한다.
- 두 번째 과정을 더 이상 수행할 수 없을 때 까지 반복한다.
BFS 구현
탐색시간은 O(N)의 소요된다. DFS보다 수행시간이 좋은 편이다.
#include <queue>
queue<int> q;
void BFS(graph, start, visited)
{
q.push_back(start);
visited[start] = true;
while(!q.empty())
{
int v = queue.pop();
for(int i : graph[v])
{
if(visited[i] == false)
{
q.push_back(i);
visited[i] = true;
}
}
}
}
int main()
{
BFS(graph, 1, visited);
}
DFS : 깊이 우선 탐색
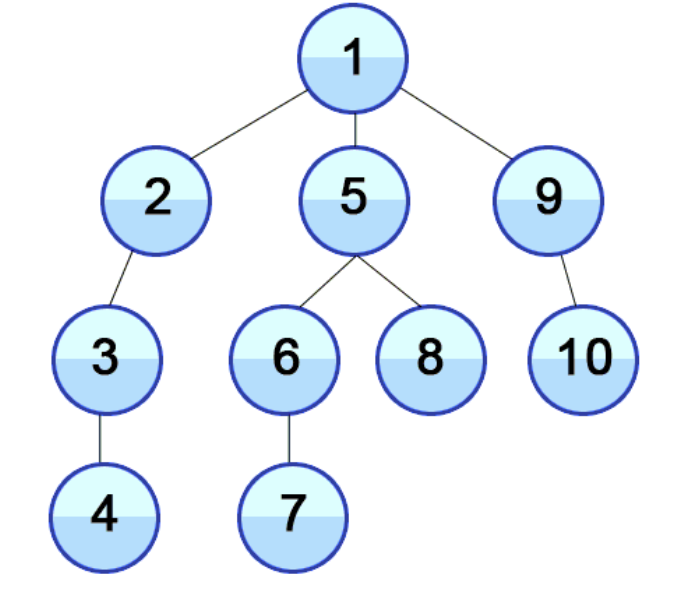
그래프/트리의 깊은 부분을 우선적으로 탐색한다.
Stack 자료구조를 이용하며 다음과 같이 동작한다.
- 탐색 시작 노드를 스택에 삽입하고 방문 처리를 한다.
- 스택의 최상단 노드에 방문하지 않은 인접 노드가 있으면 그 노드를 스택에 넣고 방문 처리를 한다. 그리고 방문하지 않은 인접 노드가 없으면 스택에서 최상단 노드를 꺼낸다.
- 두 번째 과정을 더 이상 수행할 수 없을 때까지 반복한다.
DFS 구현
탐색시간은 O(N)이 소요된다. Stack 말고 재귀함수를 이용해서 간결하게 구현할 수 있다.
void DFS(graph, v, visited[])
{
visited[v] = true;
for(int i : graph)
{
if(visited[i] == false)
DFS(graph, i, visited[]);
}
}
int main()
{
DFS(graph, 1, visited[]);
}
BFS와 DFS 비교
N: 노드 개수, E: 간선 개수 일 때,
- 인접 리스트 : O(N + E)
- 인접 행렬 : O(N^2)
일반적으로 인접 리스트 방식이 더 효율적이다.
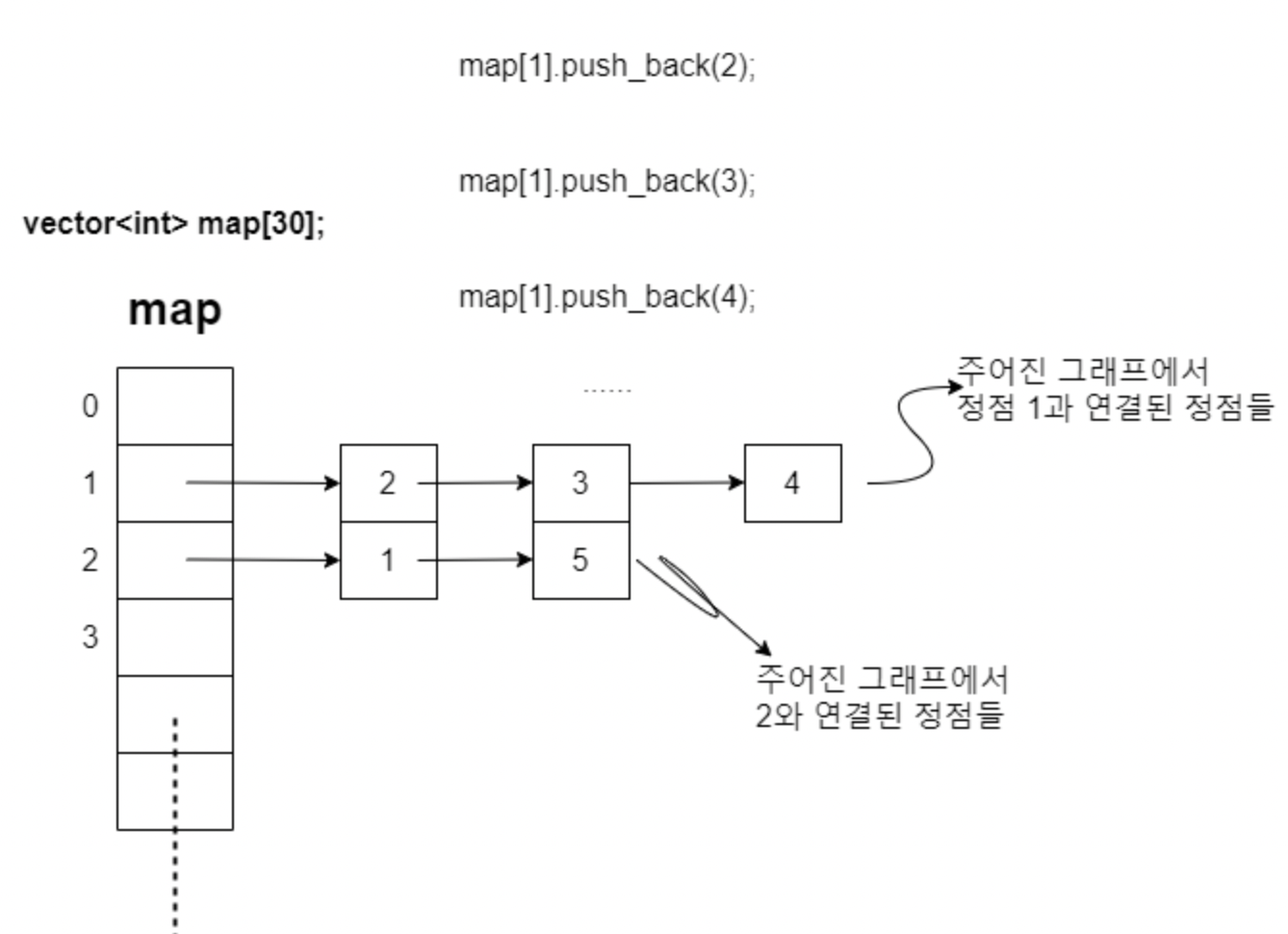
vector로 간단하게 인접 리스트를 만들 수 있다.
문제의 특징 별 DFS/BFS 활용
1. 그래프의 모든 정점을 방문하는 것이 중요한 문제
단순히 모든 정점을 방문하는 것이 중요한 문제의 경우 BFS, DFS 어느 것을 사용해도 상관없다.
2. 경로의 특징을 저장해둬야 하는 문제
예를 들어 각 정점마다 숫자가 적혀있고 a부터 b까지 가는 경로를 구하는데 경로에 같은 숫자가 있으면 안 된다는 문제 등,
각각의 경로마다 특징을 저장해둬야 하는 경우 DFS를 사용한다. (BFS는 경로의 특징을 가지지 못한다.)
3. 최단거리 구하는 문제
미로 찾기 등 최단거리를 구해야하는 경우 BFS가 유리하다.
왜냐하면 DFS로 경로를 탐색할 경우 처음으로 발견되는 해답이 최단거리가 아닐 수 있지만, BFS는 현재 노드에서 가까운 곳부터 탐색하기 때문에 경로 탐색 시 먼저 찾아지는 해답이 곧 최단거리이기 때문이다.
댓글